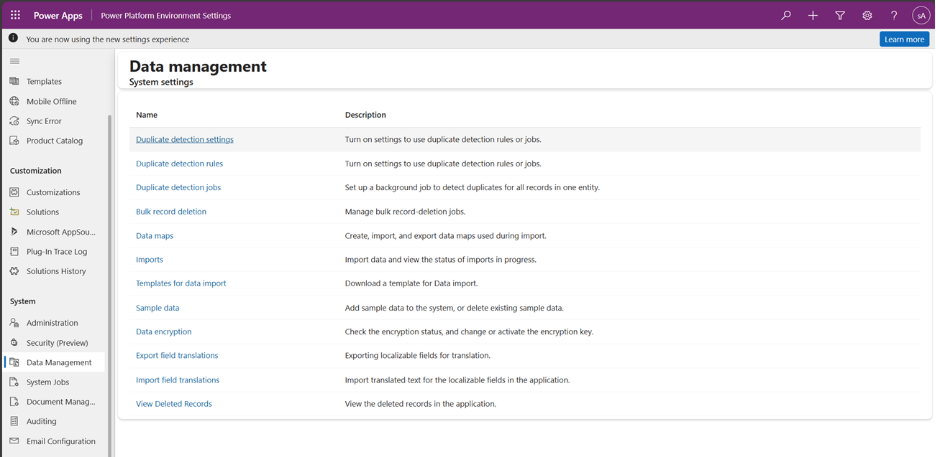
- Open Duplicate Detection Settings in the Power Platform Environment Settings app.
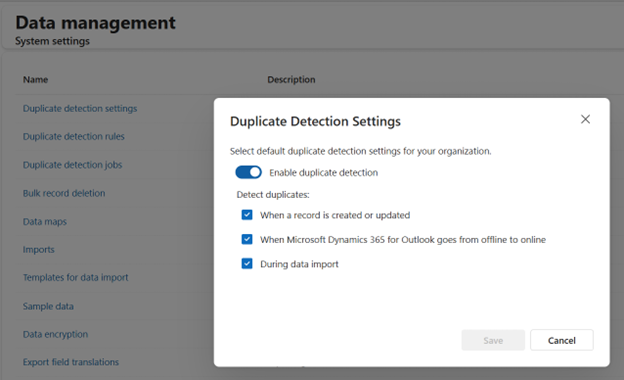
- Turn on Enable duplicate detection, in the event that it isn’t on by default.
- Choose when you want duplicate checks to run, such as:
-
- When records are created or updated
-
- During data imports
-
- Treat this as the master switch. If it is off, your rules and jobs will not help much.
Be warned, though, duplicate detection does not run for every type of data operation; specifically, high-volume API integrations and certain automated bulk imports may bypass duplicate checks. If your environment relies heavily on integrations, it’s worth validating whether those processes enforce uniqueness on their own. Volume API integrations and certain automated bulk imports may bypass duplicate checks. If your environment relies heavily on integrations, it’s worth validating whether those processes enforce uniqueness on their own. Volume API integrations and certain automated bulk imports may bypass duplicate checks. If your environment relies heavily on integrations, it’s worth validating whether those processes enforce uniqueness on their own.
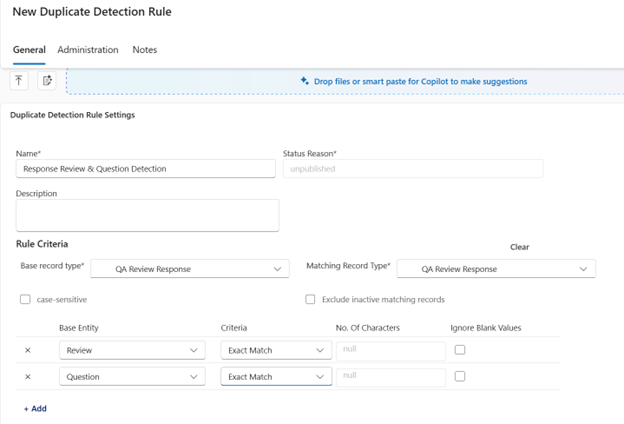
- Create a new duplicate detection rule.
-
- Set the Base Record Type and Matching Record Type. These are often the same table.
-
- Define the matching criteria fields that make a record truly “the same” in your process. Common examples include:
-
- Contacts: email address
-
- Accounts: company name + phone, or company name + website domain
-
- Custom tables: parent record + unique identifier
-
- Use rule options to reduce false positives and keep the experience user-friendly:
-
- Exclude inactive matching records so old records do not create noise
-
- Ignore blank values so empty fields do not accidentally match
-
- Case-sensitive matching for ID-style fields where capitalization matters
-
- Save and publish the rule. Publishing is a common missed step, and an unpublished rule will not behave the way you expect.
- Go to Duplicate detection jobs and create a new job.
-
- Choose what you want to scan, usually the same table you built your rule for.
-
- Decide whether to limit the scan using a view or filter, or run a broader scan if you are doing a cleanup.
-
- Run the job and review the results when it completes.
-
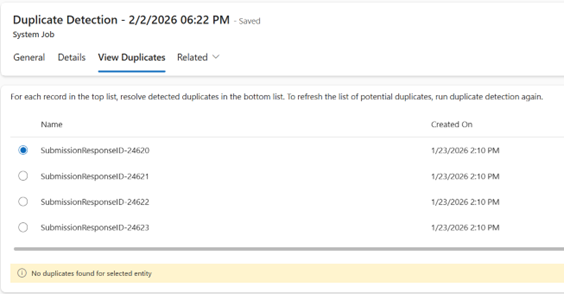
- Use the View Duplicates results to identify what needs to be merged or cleaned up.
This is where the biggest time savings shows up. Instead of spending hours searching, comparing, and deleting by hand, you get a structured list of likely duplicates that is ready for review.